
Data Mining| Machine Learning
Together with a colleague, I have been involved in the “hard” task of drafting a diagram (or a “mindmap”) that would connect logically, some of the “buzz words” regarding “data science”; e.g.: artificial intelligence, machine learning, data mining, recommenders. Moreover we wanted to provide a classification that would organize the different “algorithmic families” into some sort of typology. Hard task, I know, mostly because there are many classifications, based on the approaches we want to take; e.g.: by learning method, by task. We ended up not with one diagram, but with two, separating “data mining” and “machine learning”, in order to explain them better.
In the “Data mining” diagram, we include a general distinction between “descriptive” and “predictive” data mining, and within these two, we follow with sub divisions that finish in data mining techniques that may or not belong to machine learning (e.g.: statistics). On the bottom of the diagram, we represent the generic data mining applications, that make use of these techniques. One key difficulty in drafting this diagram is the fact that some techniques can include other techniques, and it is not easy to reflect that in the diagram. For instance, machine learning techniques typically make use descriptive statistics such as dispersion or central tendency.

In the “Machine learning” diagram we went for a more “scientific” view (less problem oriented), and tried to show how machine learning fits into the broader field “Artificial Intelligence”. Then we took the “learning approach”, as a way of classifying ML techniques. At the leafs of this tree, as well as at the leafs of the “Data Mining tree”, there are examples of techniques/algorithms relevant for the specific types; it is not an *extensive* list of algorithms, neither it claims to select the most *important* algorithm (if there is such thing…); sometimes the criteria for choosing the algorithm is greatly *subjective*: because we worked or read about it, or even because it was the only example we could find…
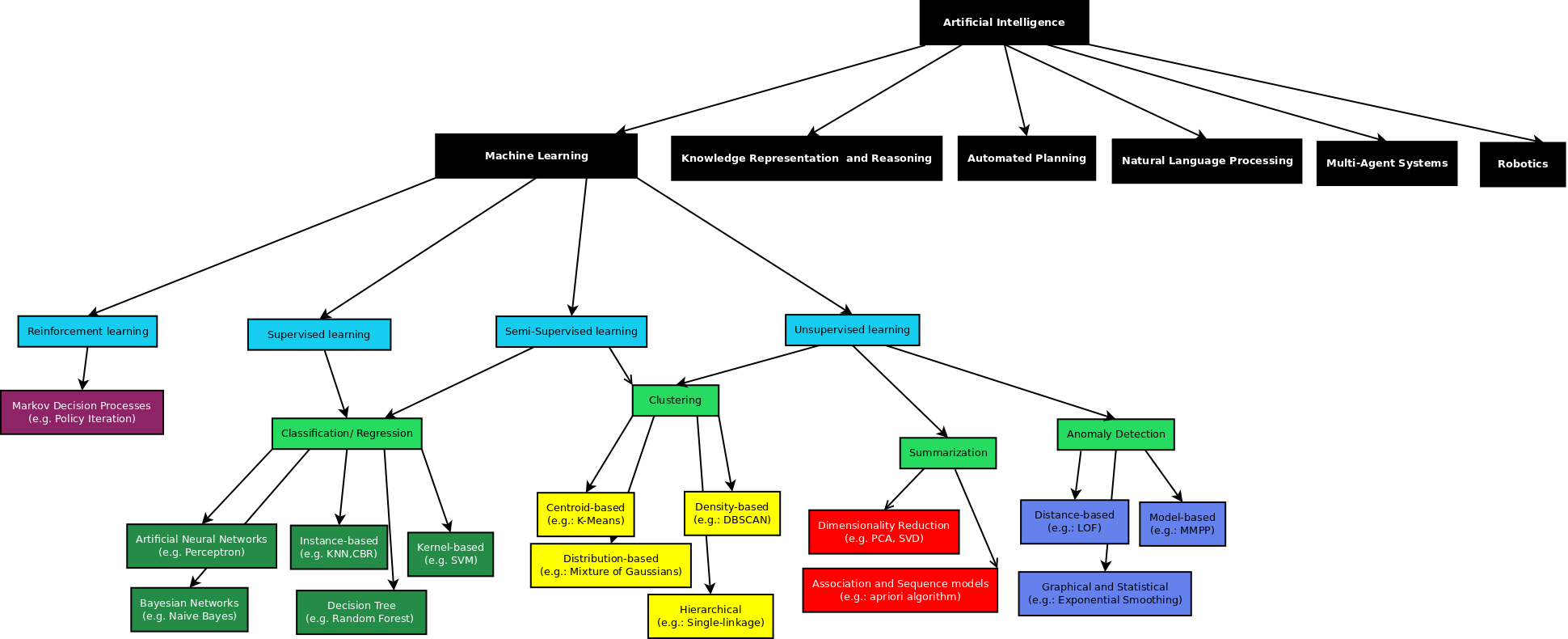
Clearly there is some degree of overlap between the two diagrams. Machine learning is part of Data Mining, and therefore some algorithmic “families” are presented in both diagrams. However we believe that in this way, it becomes easier to describe what “machine learning” is, as a scientific discipline, and how it “fits & mixes”, within the “wide umbrella” of data mining.
This diagram was based on a lot of reads (mostly blogs), on our own knowledge and a lot of discussion. It is not “written on stone”, and I don’t even know if it is possible to have such a thing, regarding a topic that is so difficult to classify, either because it is evolving so fast or because it is often very “fuzzy”. In any case, any (constructive) critics or commentaries regarding ways of improving these diagrams, or even just some thoughts would be greatly appreciated.

![]()