 Call for Papers, AAG2018: Innovations in Urban Analytics
Call for Papers, AAG2018: Innovations in Urban Analytics
We welcome paper submissions for our session at the Association of American Geographers Annual Meeting on 10-14 April, 2018, in New Orleans.
Session Description
New forms of data about people and cities, often termed ‘Big’, are fostering research that is disrupting many traditional fields. This is true in geography, and especially in those more technical branches of the discipline such as computational geography / geocomputation, spatial analytics and statistics, geographical data science, etc. These new forms of micro-level data have lead to new methodological approaches in order to better understand how urban systems behave. Increasingly, these approaches and data are being used to ask questions about how cities can be made more sustainable and efficient in the future.
This session will bring together the latest research in urban analytics. We are particularly interested in papers that engage with the following domains:
- Agent-based modelling (ABM) and individual-based modelling;
- Machine learning for urban analytics;
- Innovations in consumer data analytics for understanding urban systems;
- Real-time model calibration and data assimilation;
- Spatio-temporal data analysis;
- New data, case studies, demonstrators, and tools for the study of urban systems;
- Complex systems analysis;
- Geographic data mining and visualization;
- Frequentist and Bayesian approaches to modelling cities.
Please e-mail the abstract and key words with your expression of intent to Nick Malleson (n.s.malleson@leeds.ac.uk) by 18 October, 2017 (one week before the AAG abstract deadline). Please make sure that your abstract conforms to the AAG guidelines in relation to title, word limit and key words and as specified at: http://annualmeeting.aag.org/submit_an_abstract. An abstract should be no more than 250 words that describe the presentation’s purpose, methods, and conclusions.
For those interested specifically in the interface between research and policy, they might consider submitting their paper to the session “Computation for Public Engagement in Complex Problems” (http://www.gisagents.org/2017/10/call-for-papers-computation-for-public.html).
Key Dates
- 18 October, 2017: Abstract submission deadline. E-mail Nick Malleson by this date if you are interested in being in this session. Please submit an abstract and key words with your expression of intent.
- 23 October, 2017: Session finalization and author notification.
- 25 October, 2017: Final abstract submission to AAG, via the link above. All participants must register individually via this site. Upon registration you will be given a participant number (PIN). Send the PIN and a copy of your final abstract to Nick Malleson (n.s.malleson@leeds.ac.uk). Neither the organizers nor the AAG will edit the abstracts.
- 8 November, 2017: AAG session organization deadline. Sessions submitted to AAG for approval.
- 9-14 April, 2018: AAG Annual Meeting.
Session Organizers
- Nick Malleson, University of Leeds, UK
- Alison Heppenstall, University of Leeds, UK
- Andrew Crooks, George Mason University, US
- Tuuli Toivonen, University of Helsinki, Finland
- Alex Singleton, University of Liverpool, UK
- Ed Manley, UCL, UK
Continue reading »



 Visited the Urban Dynamics Institute (UDI) headed up Budhendra Bhaduri (Budhu) which is a rapidly growing effort in data-driven technologies applicable to cities. This group which is based at Oakridge National Labs which began life in the war years as part of …
Visited the Urban Dynamics Institute (UDI) headed up Budhendra Bhaduri (Budhu) which is a rapidly growing effort in data-driven technologies applicable to cities. This group which is based at Oakridge National Labs which began life in the war years as part of …  read my editorial in EPB: Urban Analytics and City Science, and also check out the fact that it is almost 50 years from when Alan Wilson started Environment and Planning (A) and 45 from when Lionel March started B. The …
read my editorial in EPB: Urban Analytics and City Science, and also check out the fact that it is almost 50 years from when Alan Wilson started Environment and Planning (A) and 45 from when Lionel March started B. The … 
 Here is a useful and interesting book on the nature of planning knowledge and research. My own contribution – click here to get the original PDF – is about scientific method and how theory and models pertain to the field …
Here is a useful and interesting book on the nature of planning knowledge and research. My own contribution – click here to get the original PDF – is about scientific method and how theory and models pertain to the field … 
 Two new volumes in big data, cities and regions, with a strong spatial focus. The first Seeing Cities Through Big Data: Research, Methods and Applications in Urban Informatics’ is edited by Piyushimita (Vonu) Thakuriah, Nebiyou Tilahun, and Moira Zellner and published …
Two new volumes in big data, cities and regions, with a strong spatial focus. The first Seeing Cities Through Big Data: Research, Methods and Applications in Urban Informatics’ is edited by Piyushimita (Vonu) Thakuriah, Nebiyou Tilahun, and Moira Zellner and published … 
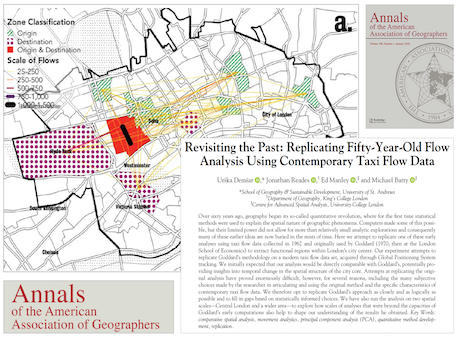 This article took 5 years in the making. We – Urskar, Jon, Ed, and myself – thought that it was a great project to see what was big data on taxi flows in central London in 1962 could be compared …
This article took 5 years in the making. We – Urskar, Jon, Ed, and myself – thought that it was a great project to see what was big data on taxi flows in central London in 1962 could be compared … 
 I gave two lectures on our smart cities projects to Geography at Nanjing Normal University and to a selection of researchers at Shenyang Jianzhu University drawn from architecture, urban planning, transport and GIS on the 25th and 27th September 2017. I …
I gave two lectures on our smart cities projects to Geography at Nanjing Normal University and to a selection of researchers at Shenyang Jianzhu University drawn from architecture, urban planning, transport and GIS on the 25th and 27th September 2017. I … 
 A new book on data and big data in the city edited by Rob Kitchin, Tracey P. Lauriault, Gavin McArdle from Routledge. Lot of very interesting material here on the data revolution in cities. Smart cities concepts are explained and critiqued …
A new book on data and big data in the city edited by Rob Kitchin, Tracey P. Lauriault, Gavin McArdle from Routledge. Lot of very interesting material here on the data revolution in cities. Smart cities concepts are explained and critiqued …  Geography Review is a brand new magazine for sixth formers (grade 12-13 in the US) studying any subject but particularly those who are interested in geography. In the UK geography is one of the top subjects in high school and …
Geography Review is a brand new magazine for sixth formers (grade 12-13 in the US) studying any subject but particularly those who are interested in geography. In the UK geography is one of the top subjects in high school and … 




 In this paper (downloadable here), I argue that the smart cities movement is simply the latest stage in the massive dissemination of digital computation that began with its invention some 70 or more years ago. In fact, the key thesis …
In this paper (downloadable here), I argue that the smart cities movement is simply the latest stage in the massive dissemination of digital computation that began with its invention some 70 or more years ago. In fact, the key thesis …  In November 1986 I visited SunYatSen University and gave a public lecture about Urban Modelling. China was a very different world then, no cars, no computers, no email, barely functioning electricity. And of course it was before laptops, networks, hand-held …
In November 1986 I visited SunYatSen University and gave a public lecture about Urban Modelling. China was a very different world then, no cars, no computers, no email, barely functioning electricity. And of course it was before laptops, networks, hand-held … 