
The name of the dataset and name of the column being visualised are shown in the top left of the map, while the colour scale is a Jenks 5 class range between the min and max of the data. This sort of works, but raises more questions than it answers about the data. To start with, one interesting thing that jumps out of the data is that there was a step change in London population around 1939, from the “London Borough Historic Population” dataset.
The first problem with this is that there is no structure to how the thumbnail maps are placed on the image. The idea is to use a data classifier and group maps according to how similar they are, so distance would be proportional to similarity. This work is still in progress.
The next problem is with the colour scales, as it commits the cardinal sin of not showing one. The maps are supposed to be representative, so all use the green Jenks 5 classes, but it’s obvious that this has gone wrong on most of the maps. The reason for this is that the London Datastore include data in the CSV files at different geographic scales. Most of the maps show London at Borough level, but also contain data for England, Scotland and Wales which mess up the automatic colour scale. The top range ends up being the larger geographic areas which you can’t see, so the maps end up with just four classes on them. On some of the maps you can see the Government Office Regions (Midlands, Wales, South East etc), along with Borough level data for London.
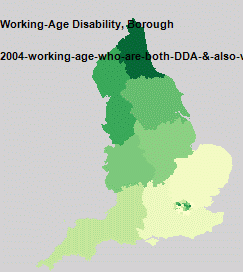
A map showing data at different geographic scales. London has data at Borough level while the rest of the country is at GOR level.
The final problem, which also relates to different geographic scales, is to do with almost all the maps visualising either a count of people or events. Most maps are a population of some kind, so displaying population density rather than count would make a lot more sense.
As a proof of concept, this demonstrates that we can handle the maps automatically from an Internet data store. One thing that’s obvious from looking at the zoomable map view is that you need the ability to click on one of the thumbnails and go straight through to the full size map with all the information about what is it. There is also no search facility so you can’t find anything, but the next proof of concept is where things will start to get interesting….
We will be following progress and the forthcoming TALISMAN project blog with more results in the new year.





